
El archivo robots.txt es una herramienta clave en SEO técnico. Aunque no afecta directamente al ranking de una web, una configuración correcta mejora la indexación y ayuda a los motores de búsqueda a priorizar las páginas más importantes. En esta guía completa, te explicaré qué es, cómo funciona y cómo optimizarlo para evitar errores que puedan impactar tu visibilidad online.
¡Vamos allá!
- Qué es el archivo robots.txt
- Por qué es importante el archivo robots.txt
- Cómo funciona el archivo robots.txt
- Errores comunes en la configuración del archivo robots.txt
- Cómo configurar el archivo robots.txt
- Ejemplos de robots.txt
- Configuración básica para permitir el rastreo de toda la web
- 👉 ¿Cuándo usarlo? – Configuración básica robots.txt
- Bloquear todo el sitio web
- 👉 ¿Cuándo usarlo? – Disallow en robots.txt
- Bloquear directorios específicos
- 👉 ¿Cuándo usarlo? – Disallow de directorios en robots.txt
- Permitir recursos específicos dentro de un directorio bloqueado
- 👉 ¿Cuándo usarlo? – Allow recursos específicos en robots.txt
- Bloquear URLs con parámetros dinámicos
- 👉 ¿Cuándo usarlo? – Disallow parámetros en robots.txt
- Permitir solo el rastreo a Googlebot y bloquear otros bots
- 👉 ¿Cuándo usarlo? – Allow Googlebot, disallow resto de bots
- Bloquear imágenes para Google images
- 👉 ¿Cuándo usarlo? – Disallow imagenes en google images
- Bloquear el rastreo de páginas con extensiones específicas
- 👉 ¿Cuándo usarlo? – Disallow ciertas extensiones en robots.txt
- Cómo probar y validad el archivo robots.txt
- Recursos de Interés para Optimizar tu Archivo robots.txt
Qué es el archivo robots.txt
El archivo robots.txt, no es más que un archivo de texto que se coloca en el directorio raíz de una web. Este archivo contienen unas instrucciones, llamadas directivas, que indican a los bots (como las arañas de los motores de búsqueda) qué partes de la web pueden o no ser rastreadas.

Si quieres conocer los diferentes bots de rastreo de Google, te dejo un enlace a su documentación oficial.
👉Fases de Google antes de posicionar una web
¿Te gustaría conocer cuáles son las fases por las que toda web pasa para que Google la indexe en su índice? Lee el artículo 5 etapas clave antes de que Google posicione
Por qué es importante el archivo robots.txt
La correcta optimización de robots.txt es importante para el SEO, sobre todo en páginas web que tienen un gran número de URLs, ya que permite:
Google y los motores de búsqueda en general, asignan un presupuesto de rastreo (crawl budget) a cada web. Es decir, cada vez que un robot pasa por nuestra página para rastrearla y ver nuestro contenido, tiene un tiempo limitado. Al optimizar el archivo robots.txt podemos dirigir ese presupuesto hacia las páginas más importantes, asegurándonos que Google pase por nuestras páginas más relevantes y no pierda el tiempo con páginas menos relevantes para nuestro negocio.
Bloquear recursos innecesarios cómo páginas de carrito, contenido duplicado… mejora el rendimiento del sitio y reduce la carga del servidor, lo que conlleva a una mejor experiencia de navegación para los usuarios.
Cómo funciona el archivo robots.txt
El archivo robots.txt usa unas directivas, instrucciones o reglas específicas para controlar el comportamiento de los bots. Estas directivas son:
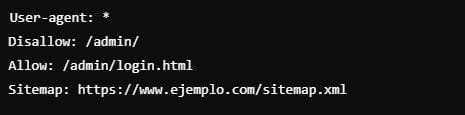
En el ejemplo anterior, todos los bots tienen prohibido rastrear el directorio /admin/, pero si tienen acceso a la página login.html dentro del directorio admin.
Errores comunes en la configuración del archivo robots.txt
Este archivo puede dar error si no tenemos una buena configuración. Algunos de los errores más comunes son:
- Errores en el sitio web: por ejemplo si nuestra web tiene muchas páginas con el código de estado 404 o 410.
- Errores del servidor: código de estado 500
- Bloquear páginas importantes, incluso algunas veces (por accidente), se puede bloquear todo el sitio web. (Por una mala implementación de las directivas).
- Bloquear archivos JavaScript y CSS, esto tendrá un impacto en el renderizado del sitio web. Si bloqueamos archivos JavaScript, pueda ser que Google no pueda visualizar parte de nuestro contenido, y si bloqueamos las hojas de estilo CSS, puede ser que Google no considere que nuestra web es responsive y no nos la tenga en consideración. (Ya que Google prioriza el bot de smartphone)
- Robots.txt responde con un error 404: en este caso, Google rastreará toda la web, sin restricción alguna.
- Robots.txt responde con código de estado 500: éste es el peor de los escenarios ya que este código se refiere a un error de servidor. Google lo entiende como que existe una sobrecarga en nuestra web y el robot de Google no quiere aumentar más esa sobrecarga prefiriendo no rastrear nuestro sitio.
Cómo configurar el archivo robots.txt
Teniendo en cuenta los errores que podríamos tener en este archivo, voy a enumerar cómo podríamos configurarlo y hacer uso de buenas prácticas.
- El archivo robots.txt siempre tiene que estar en el directorio raíz de la web
👉 Tip SEO – Robots.txt estado 200
Queremos que el archivo robots.txt nos de un código de estado 200, por lo que no puede tener ningún tipo de redirección. (Siempre robots.txt en la raíz principal del sitio)
- Gestiona subdominios separadamente: cada subdominio debe tener su propio archivo robots.txt

Si nuestro sitio web es «ejemplo.com«, y creamos un subdominio llamado blog, debemos tener dos robots.txt uno para «ejemplo.com/robots.txt» y otro para «blog.ejemplo.com/robots.txt«.
👉 Tip SEO – Subdominios y robots.txt
Google trata los subdominios cómo páginas web diferentes al dominio principal.
- Bloquea solo lo necesario: restringe páginas que no tengan valor SEO.
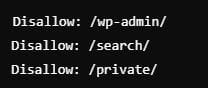
En este ejemplo hemos bloqueado la sección de admin, de búsqueda y el área privada, pero también podríamos bloquear, carritos de compras, contenidos duplicados, es decir, páginas no relevantes para el SEO ni para nuestro negocio, impidiendo así mal gastar el presupuesto de rastreo que Google tiene para nuestro sitio.
👉 Tip SEO – Buenas prácticas robots.txt
Evita bloquear páginas que contienen contenido valioso o recursos esenciales para el renderizado.
- Incluye el sitemap.xml: facilita la indexación añadiendo la ubicación del mapa del sitio XML

- Monitorea los cambios: existen herramientas que nos permiten recibir alertas si se modifica el archivo robot.txt
👉 Tip SEO – Sitemap en robots.txt
Utiliza herramientas como ContentKing o Google Search Console (GSC) para ver cambios en el robots.txt
Ejemplos de robots.txt
Configuración básica para permitir el rastreo de toda la web
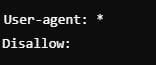
👉 ¿Cuándo usarlo? – Configuración básica robots.txt
Cuando deseas que todo el contenido de tu sitio sea accesible para los motores de búsqueda
Bloquear todo el sitio web
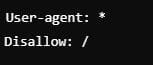
👉 ¿Cuándo usarlo? – Disallow en robots.txt
Impide que cualquier bot rastree el sitio completo. Este caso nos puede ser útil cuando nuestro sitio está en desarrollo o mantenimiento
Bloquear directorios específicos
Prohíbe el rastreo de directorios internos como /admin/, /cgi-bin/ y /test/, pero permite que el resto del sitio sea rastreado.
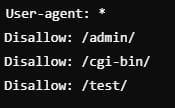
👉 ¿Cuándo usarlo? – Disallow de directorios en robots.txt
Cuando queramos proteger áreas internas o administrativas no relevantes para la indexación
Permitir recursos específicos dentro de un directorio bloqueado
Permite el acceso a ciertos archivos específicos dentro de un directorio bloqueado. En este ejemplo se está permitiendo el acceso a recursos css y JavaScript.
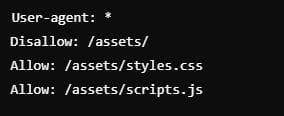
👉 ¿Cuándo usarlo? – Allow recursos específicos en robots.txt
Cuándo necesitas que Google renderice adecuadamente las páginas mientras bloqueas otros recursos no necesarios.
Bloquear URLs con parámetros dinámicos
Restringe el rastreo de URLs con parámetros que podrían generar contenido duplicado o innecesario.
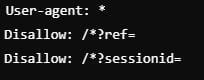
👉 ¿Cuándo usarlo? – Disallow parámetros en robots.txt
Cuando queremos evitar problemas de contenido duplicado causado por parámetros de URLs
Permitir solo el rastreo a Googlebot y bloquear otros bots
Restringe el acceso a todos los bots excepto a Googlebot
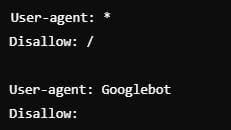
👉 ¿Cuándo usarlo? – Allow Googlebot, disallow resto de bots
Cuando solo deseas que Google rastree tu sitio mientras restringes otros bots como pueden ser bots de herramientas de scraping.
Bloquear imágenes para Google images
Evita que Google indexe imágenes de tu web, protegiendo contenido visual sensible.

👉 ¿Cuándo usarlo? – Disallow imagenes en google images
Si por alguna razón quieres evitar que tus imágenes aparezcan en los resultados de búsqueda de Google Images.
Bloquear el rastreo de páginas con extensiones específicas
Impide el rastreo de archivos con ciertas extensiones. En este ejemplo extension .pdf o .doc
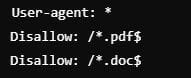
👉 ¿Cuándo usarlo? – Disallow ciertas extensiones en robots.txt
Si tienes documentos internos que no deben ser indexados pero que son accesibles públicamente.
Ten en cuenta, que estos son sólo unos pocos ejemplos de cómo se podría configurar este archivo, sin embargo, debemos adaptarlo a las necesidades específicas de cada sitio web.
Cómo probar y validad el archivo robots.txt
Podemos comprobar su correcto funcionamiento de manera manual o automática.
Si decidimos comprobarlo manualmente lo único que tenemos que hacer es indicar el dominio de la web/ robots.txt

También podemos utilizar extensiones como por ejemplo Robots Exclusion Checker.
Para finalizar este post, me gustaría recalcar, que el archivo robots.txt es una herramienta poderosa para gestionar el comportamiento de los motores de búsqueda en los sitios web. Su correcta configuración puede mejorar significativamente la eficiencia del rastreo, proteger contenido sensible y optimizar la experiencia de usuario.
Siempre debemos asegurarnos de seguir las mejores prácticas y comprobar regularmente nuestro archivo para evitar errores que puedan afectar nuestro SEO.
Recursos de Interés para Optimizar tu Archivo robots.txt
Si queréis profundizar más acerca del robots.txt os facilito los enlaces a la documentación oficial.
Consultora SEO. Mi pasión está en el SEO Técnico y en exprimir al máximo la Inteligencia Artificial. En SirimiriDigital analizo cómo la tecnología transforma las búsquedas para explicártelo de forma sencilla, práctica y accionable.